Hi there!
This are some ideas that stem from the discussions that took place in the gathering and the session we had yesterday morning with Rachel and Dani in Barcelona.
I’ll try to describe what is it that we want to achieve piece by piece in a way that everyone understands.
Need
Local and global business intelligence
This is the need we have. At local level, we want to answer all sorts of questions around the usage of the platform: how many organizations where created in the last month, total turnover of these organizations, how many user hubs have, etc.
Also, we need to know how much we have to charge our customers based on their membership and turnover each month effortlessly.
At a global level, we need to answer these questions with a single global view which could help in future funding applications.
Alerts for OFN instances
We have also the need to know when a new profile gets created in OFN as well a shop set up as this would mean we have a new customer to charge in the next billing cycle.
We need to get notified instead of us having to check periodically as this requires extra effort and it’s error-prone.
Solution
Metabase
This open source business intelligence would the insights we listed above by means of its core concepts questions and answers. The former is any data we get from a database table using filters, agreggations and grouping (aka. SQL queries with an awesome UI). Then, answers can be visualized in many ways: numbers, line charts, funnels or even maps.
The other two powerful concepts built on top of questions are:
Segments
a special named filter or set of filters. You can create these to make sure that there is an official definition of a subset of customers that everyone on your team can refer to consistently. For example, you might create a segment called “Active Users” that contains all the filters that are needed to correctly select active users.
Metrics
an easy way to refer to a computed number that you reference often. This could be something like revenue, which you could arrive at by viewing the Sum of your Order’s Subtotal column, and applying any required filters — but it’s a pain to have to do this every time you want to do something with revenue.
Then, we can arrange questions based on agreed segments and metrics in meaningful dashboards and collections. We would share segments like active users, producers and metrics like turnover.
Lastly, Metabase also has Pulses which are either email or slack notifications based on saved question.
This way we can set up Metabase to know how much we should charge our customers each month like I start doing below. Generating invoices is something that only Zappier covers and Metabase won’t.
I want to be crystal clear on the fact that to use it we need to be familiar with databases. There’s a lot that Metabase abstracts but still, it is all around database tables and the information each one contains and therefore, a basic understanding of the data model is also necessary.
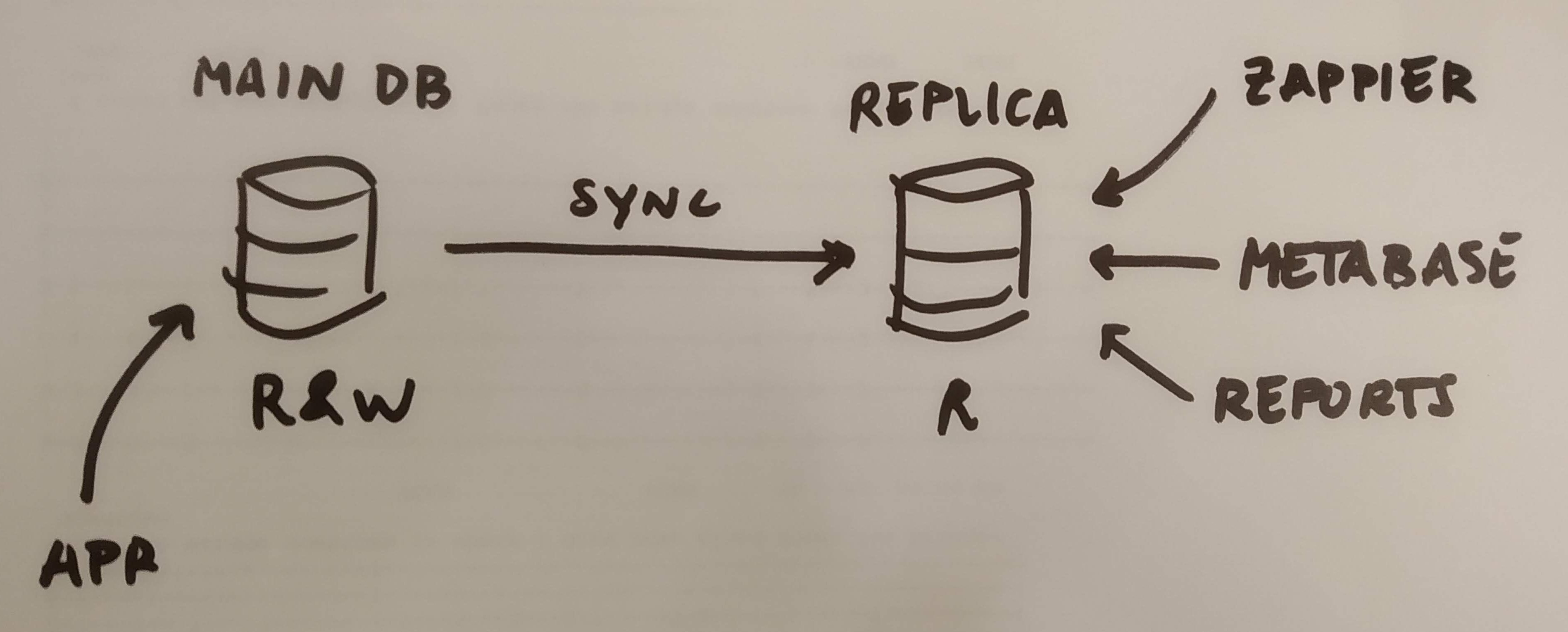
Database read-only replica
Aka. having a separate database server that is in sync with the main one but which we can only use to read data from. This time, shared amongst all instances, so we move towards a single infrastructure.
Why? because it will enable Local business intelligence and Global business intelligence by means of Metabase but also:
- Generate reports without causing trouble to other users as they’ll fetch data from this separate read-only replica. This should also bring some speed improvements.
From an architecture perspective this looks like
Pilots
To move this forward we suggest the following pilots
1. Katuma starts using a global Metabase instance
With this we want to prove that Metabase covers:
- our immediate data per shop needs, now that we have pricing plans and new hubs as members of the coop who need to be charged.
- our need to understand whether our efforts on user acquisition pay off or not and the overall growth of the instance.
- the necessary alerting needs so that we get notified whenever new shops appear on the platform.
- the need to know how much to charge our customers each month.
Why Katuma? Australia and UK have these needs somewhat covered with the current Zappier solution while France still has some room as they will start charging customers in September at the earliest. Other instances still don’t have defined pricing plans. Am I right?
This requires the aforementioned database read-only replica and needs a tech solution.
2. Onboard France to Metabase
With this next pilot we want to prove that Metabase also covers:
- The need to have consistent data across instances which allows comparing data between instances
- single view of global data, which has a big impact on potential funding applications.
Beyond here
We believe that Metabase does cover our data and alerting needs but it does not help us automating the per-shop invoice generation that all instances need which we think involves integrating Zappier with our accounting solutions.
Then, as a separate topic we could make reports fetch the data from this database replica as mentioned above.
Finally, there some privacy concerns that need to be answered: where this Metabase server will be located, whether we need to mask any personal data such as phone numbers, names and stating this data collection in our privacy policy.
Tech
The necessary discussion around technical solutions needs to happen after we agree on the whys and the pilots, not before.
 this is really exciting!!
this is really exciting!!