What follows is a brief description of the incident that happened on 03/20/2019 02:47 PM UTC and lasted until on 03/20/2019 04:27 PM UTC.
Summary
Postgres got stuck and didn’t process any new requests causing the app to be down for 1h and 46min. The issue didn’t get resolved until we restarted Postgres for a second time.
Impact
All users using Open Food France at that time impacted.
Root Causes
We don’t have data to claim the hypothesis but possibly a deadlock or a very long UPDATE statement caused Postgres not to respond. See image below.
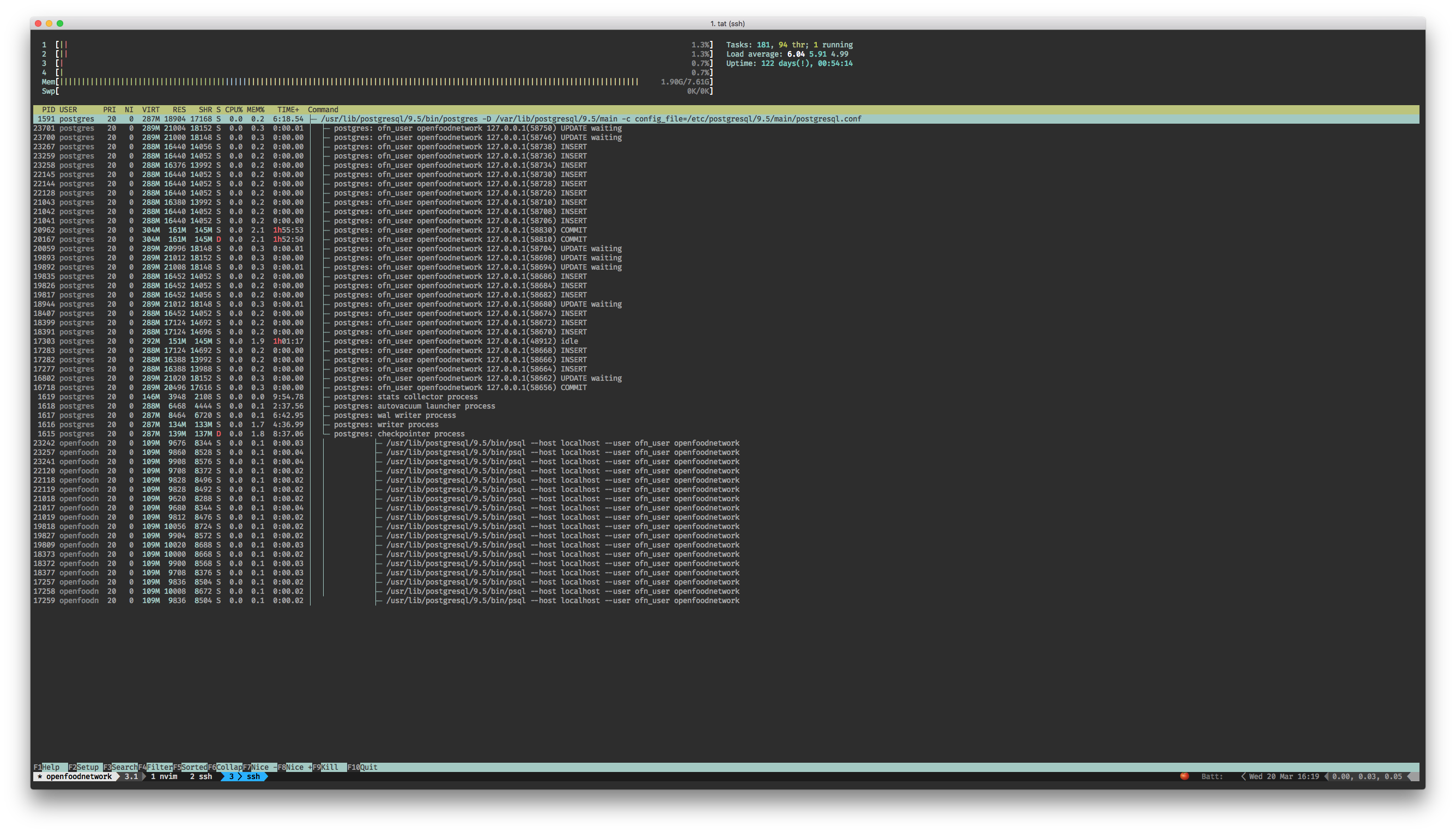
Trigger
Chances are that the culprit statement/s were issued by a background job.
Resolution
Proceeded to kill what seemed to be the stuck process and restarted Postgres. However, it took a while for the server to actually kill the process. Below you can see a COMMIT statement blocking the restart.
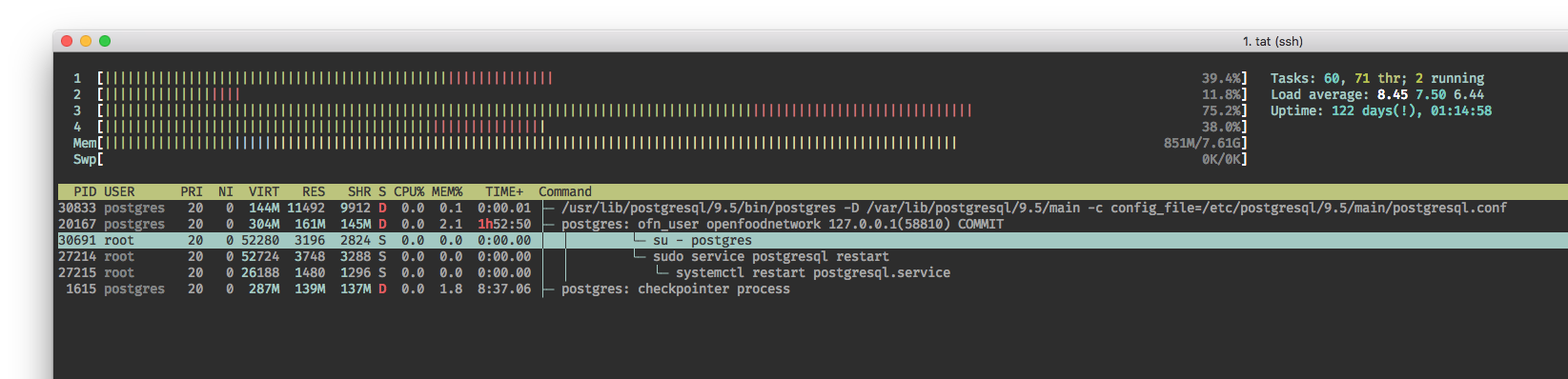
Then, we stopped Unicorn and Nginx to prevent any new requests but Postgres got stuck with the process line postgres: startup process recovering after the restart.
A strace on the main Postgres process pointed out that the process was sort of looping on a bunch of instructions. We then killed that process and started it again through systemd and it finally worked.
We then proceeded to start Unicorn and Nginx back again.
Detection
I saw the fr-prod-happy-apps alarm in #devops-notifications regarding production and when I went check Datadog a saw an abnormal CPU I/O wait. See image below.

You can check out the incident alarm at https://app.happyapps.io/incidents/890519
Action Items
See Change to a Datadog’s paid plan and Enable PostgreSQL detailed logging in Making operations a first-class citizen.
I also suggest we create a postmortem category for these reports.
Lessons Learned
What went well
- The team acted very quickly and without panicking


- All team members involved contributed with ideas to fix the issue
- Datadog’s infrastructure monitoring was very useful to spot the impact of the incident.
- A Slack thread provided to be a great way to communicate while serving as history of the event.
What went wrong
- It took us long to figure out that the only way to solve it was stopping Postgres.
- We have no experience in responding to such incidents.
- We don’t have any mechanism to know when Postgres is not performing as expected so there’s no way to actually know what is going on.
Where we got lucky
- Stopping, killing and restart processes didn’t cause data loss, as far as we know.
Timeline
Check out the Slack thread