Cool, sounds like progress. What environment is the server running in? I know for some reason the default for the ansible scripts was to set the server to run in the test environment, which makes no sense, and also would stop bugsnag from reporting errors. It looks like that might be the case, since the logs are appearing in log/test.log. Could you try setting it up in development instead? The easiest way to do that might be to re-run the provisioning with rails_env set to development in vars.yml.
Alternatively, for a quick test, you could try putting “test” in the bugsnag notify_release_stages var.
OK. I had just done vagrant reload, but will try that next time. Looks like some new (and prosaic) output in the log file now: http://pastebin.com/Y24FSqJj
Hey in the non-test environment (with rails_env set to development in vars.yml) we get further! There was first a page with message about missing fields. Then:
I’m not sure how to get around this. Interestingly, when I start the rails server it says:
Rails 3.2.21 application starting in development on http://0.0.0.0:3000
The 8080 of course is set in the Vagrant file. Any recommendations? Maybe I could make a setting in the host computers /etc/hosts file, but it seems like there might be a more “elegant” approach.
Hi guys - not sure if rohan mentioned that he’s away again for 10 days, but then he’s really back. @maikel may have some ideas on this but poss. not til next week - so silence is not forgotten / ignoring just significant resource limitations!!
Interesting. It looks like the rails application is not allowed to make web requests. I’m wondering if that could be because of the environment. Try staging or production.
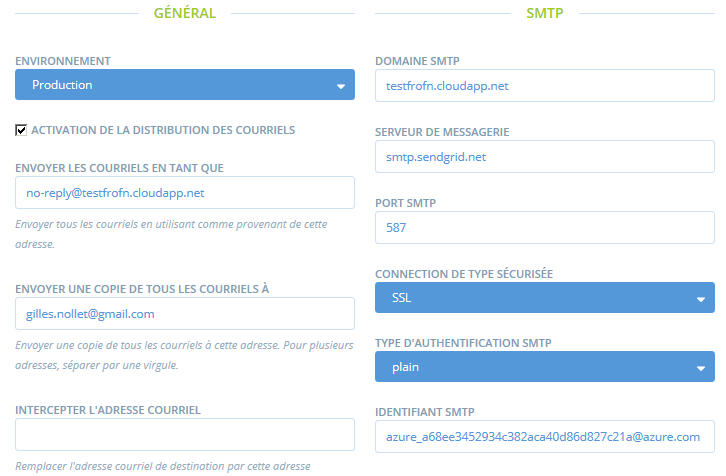
Hi, I try to install production with ansible, then now I’m able to create enterprise but email is not sent.
From email configuration panel, I can send test email.
About email confirmation, I just see this message : “translation missing: fr.devise.enterprise_confirmations.enterprise.confirmation_sent” but no error.
@gnollet I wasn’t able to download the log file that you referenced (I get a 404). However, I wrote up some email issues that @maikel and I found on the UK server. Perhaps one of those would be helpful for getting this up and running?
Then I can send a test email, I receive it.
But when I create an enterprise, I didin’t receive the email then I can’t validate contact information and can’t complete enterprise registration.
The log file I put on the link is no more available because I reinstall the OFN application with ansible playbook to try the production envirronement.
Great, sounds like moving to production environment is a step in the right direction. @gnollet, could you send me the current log files (production.log and delayed_job.log) so I can have a hunt for causes of the problem sending emails?
It looks like this is a tricky problem to track down from a distance. Would you be open to giving @maikel or myself SSH access to the server so we can have a go at tracking down and fixing the problem? I reckon that might be a more efficient way to proceed, and we could write up whatever we found so that the problem and solution are documented for future users. I’ll be away for the next week (until the 29th of October), but Maikel will be available for that time.
I’m not sure if this is related to your problems at all, but I will just document one problem solution for the UK staging server. Just to understand the whole architacture of emailing:
A mail method is configured in Spree (prod/stage dependend).
When a mail should be sent, that job is stored in the database.
A separate process (delayed_job) picks up jobs from the database and sends the email.
Delayed_job is started by a program called monit.
Monit has a system configuration file for delayed_job and checks every two minutes if delayed_job is running, restarting it if needed.
You see, there is a lot that can go wrong. For the UK, I checked the single steps to see what is working and what is not. One problem there was that monit was configured, but could not start delayed_job. There should be a file /etc/monit/conf.d/openfoodnetwork containing this:
check process openfoodnetwork_dj_worker_0
with pidfile /home/ubuntu/apps/openfoodnetwork/current/tmp/pids/delayed_job.0.pid
start program = "/bin/bash -c 'RAILS_ENV=staging /home/ubuntu/delayed_job.sh -i 0 start'"
as uid ubuntu and gid ubuntu
with timeout 120 seconds
stop program = "/bin/bash -c 'RAILS_ENV=staging /home/ubuntu/delayed_job.sh -i 0 stop'"
as uid ubuntu and gid ubuntu
with timeout 120 seconds
if mem is greater than 250.0 MB for 3 cycles then restart
There is a reference to /home/ubuntu/delayed_job.sh, it was manually added by me. The original script pointed to delayed_job.sh the repository’s script folder. Unfortunately, that script contains paths specific to the Australian servers. I needed to copy it and edit the paths. Then restart monit as root (careful: service monit restart as user doesn’t give a good error message, but doesn’t not reload the system configuration either).
I’m not sure if that is solved in the latest version of the deploy scripts, but it definitely needs attention. Otherwise email just won’t work.
@MikeiLL, you fix the issue !
The delayed_job.sh script is setup with wrong paths, as you mention, the ansible paths are not used in this script.
I change the paths on delayed_job.sh script ans start it manually, I receive the emails I’m waiting.