@Matt-Yorkley
You seem to be preemptively starting on this evenings discussions.
Have you joined the Miro board yet?
@Matt-Yorkley
You seem to be preemptively starting on this evenings discussions.
Have you joined the Miro board yet?
@Matt-Yorkley the dfc doc is under construction. It’s written by the people who are implementing it 
Unless you are speaking about JSON-LD standard doc? I’d be curious to learn more in that case. Devs from the food assembly and others competitors validated that approach because (and I quote I don’t understand what I’m saying) “JSON-LD is basically just adding a header in the request”. So they were all super happy with the standard. Of course it’s also a chicken egg problem…
Orders endpoint is used in Aus in a bunch of zaps. I can cope with changes as long as @lin_d_hop can and provides the adapted scripts to add up all the adjustments, shipping, payment etc 
Maybe this is an issue for another time, but… that one order endpoint that everyone uses for zaps should probably be split into 3 different endpoints. I think the way it currently works would probably be classed as bad API design…
*runs away and hides*
Hi folks,
Thanks for an interesting session last night.
I’ve made some notes that capture what I consider to be the main insights here.
Just a reminder that we’ve added a next meeting about this: 8pm GMT Thursday January 28th.
I am currently in the process of documenting a proposal for what happens next… just trying to organise my thoughts to try and keep the posts short.
Dear all,
thank you so much for working on this critical topic! Even though you had the meeting yesterday already, I would like to share what we (the German instance) are doing and what we are planning with the API. I hope this is still of interest - worst case it is just one more supporting voice to keep going…
What we are doing with the API:
What we are planning with the API:
From a technical point of view @hhomann is in the lead in our instance and he keeps stressing that this API development is very, very, very important for us. Having it would be a real game changer - you are obviously more than aware of this!
Is it possible to give an estimation timewise? Are we talking months or years?
Thanks, have a great weekend!
Hi @konrad
It would be very helpful if you would share details of the endpoints including the specific fields you are using so we be sure to include this knowledge in planning. As the API is not officially supported, without this information we might make breaking changes to your integrations.
Thanks for being proactive!
Lynne
Hi @lin_d_hop,
Currently we are using these endpoints:
api/orders
api/orders/{order_number}
api/products/bulk_products
api/products/{product_id}
according to our developer we are using all fields. Let me know if you need any further information. Looking forward to the future API
Just throwing this out there: in terms of drawing up a plan for work that would need to be done to start improving the API, I think it would look identical whether we went with React or Reactive Rails. Both the specific work we should probably start doing now in terms of clean-up and laying some good foundations, and the general roadmap for how to proceed after that point would be exactly the same…
I think Matt is right. This API clean up can be done before decision is done on the react/reactive side.
There’s only the question of, if we go reactive, how to reuse code between API and reactive controllers. But I think that can be thought about afterwards.
1) The existing Rest API gives us a significant head start on meeting our API needs
No surprises that working from our existing REST API provides a significant head start on some specific use cases of our API. There are considerations about whether the head start will be more costly later.
2) The needs of instances/users of the API are different to the needs of the app
The needs of instances/users are focused around two main goals - to integrate with other tools or to enable flexibility of CRUD operations on OFN data. This is much more focused than the needs of the app to totally support dogfooding.
3) Reactive Rails is preferred in the team
The advantages of faster dev and more flexibility in scaling the team back if necessary seemed to be preferred over the alternative advantages of dogfooding our API and using a more established framework. A five year minimum estimate on ReactiveRails support felt like a sufficient horizon. Being able to easily reduce the dev team if funding became scarce was a key advantage.
4) The DFC approach better fits our vision.
The DFC is more difficult to develop, but has a much higher value when considered alongside our vision and values.
1. We commit to Reactive Rails
Overall my interpretation is that the group is leaning to ‘fast dev, flexible team’ over ‘established best practice’ which, again in my interpretation, feels fitting to our current market position.
I know that the community agreed this in the past and it was mostly my realisation that we would cease to be dogfooding our API that has slowed this down. I know I was not alone in wanting to investigate this further but I hope this is increasingly a less controversial proposal.
2. We define a product strategy for our API
With the above decision the API becomes a product independent of the app. This means that it needs an independent product strategy. Given our current starting point of two APIs the need for a clear strategy to avoid duplication of tasks and bugs is incredibly important.
When considering the needs around the API two key themes emerge:
Conveniently we also have two APIs with specialisations toward these different needs.
I would like us to spend our session on Thursday unpacking this further.
8pm GMT Thursday 28th Jan
Agenda Point 1 - A decision on our FE Framework Strategy
See above and here for background.
Agenda Point 2 - Towards our API Product Strategy
The key to our API strategy will be in understanding if we have two sufficiently different usages for our API to warrant two different products. Or should we be seeking to converge on a single API in the near future?
To try and tease this out we can explore the following questions:
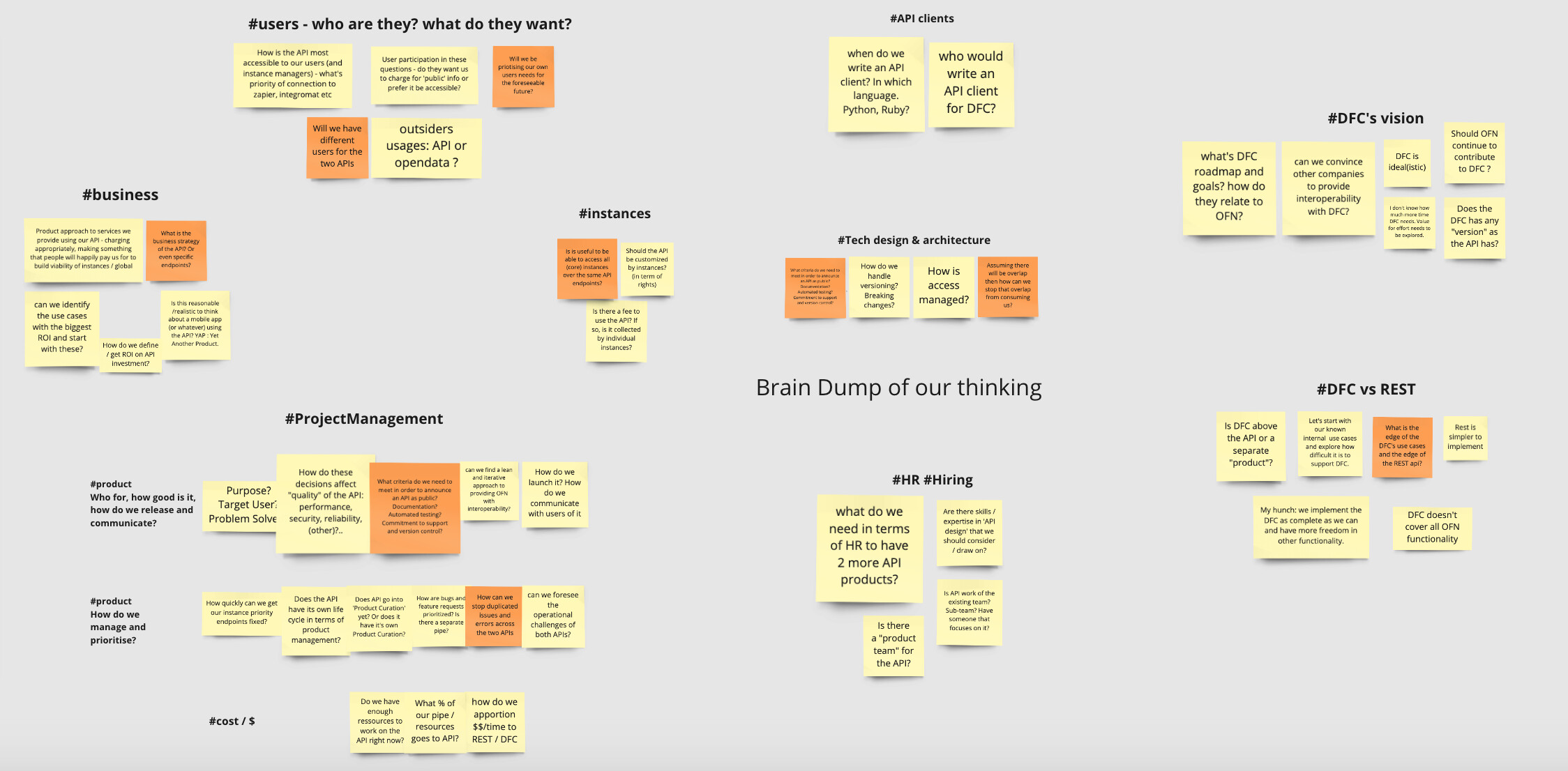
I’ll add some facilitation prep to this Miro board in preparation for the session.
Update for those who weren’t there, and next steps
At the previous meeting we:
The notes from the brainstorm are now clustered and can be seen here and pasted below
The questions / issues for discussion can be summarised (pretty much as @lin_d_hop anticipated) as:
@sauloperez and I are proposing that in the next session we focus on identifying the core / most important user of our API and discuss the questions of business model / API in this context.
If we knock that off easily, we can move onto the preliminary Product questions re. ‘MVP’ what will V1 released API look like and include.
If you can before Friday meeting, it would be great if you can go into the miro and the new grey box at bottom left, and put any thoughts on Users and expected / desired Value created by our API
We had a discussion about this in our OFN-CAN and OFN-NA meeting today. We are not totally clear if now is the time (Before your meeting Friday) for us to contribute here - or not. None of us know exactly what an api endpoint is - but we do know the kinds of use cases we imagine.
Should we be listing input somewhere or are we waiting on a different step? Thanks.
Yes please @tschumilas and CA team. Please capture your use cases here.
Thanks for the meeting exploring business and core user last night.
I understand that these questions might be a bit early considering the process that happened last night, but they are very real questions I have as I create issues for the tax reports. In the initial proposals of the tax reports our intention was that these reports will have API endpoints. It might be an opportunity to release our first officially supported endpoints… or it might not.
The following questions will be helpful in understanding the overhead to creating these endpoints as the first officially supported. I am currently unsure whether officially supporting these endpoints within the tax reports work will constitute unacceptable scope creep… or if it is a good opportunity
The questions I currently have can be answered by our specialist circles, hence I’m asking them async rather than in a meeting with everyone:
(particularly @Matt-Yorkley)
This is a lot of questions… Probably others have more. These are just the ones that I feel like are blocking me in the next step on the tax reports work. Insights appreciated
Can I clarify what “officially supported endpoints” means?
Does it mean that if there is an s2 on these endpoints we treat it as an s2 or does it mean we do a big release for people external to OFN to do stuff with it?
To me ‘officially supporting’ means that we have a bug process and a rollout process for the API. It is more agile than ‘a big release’. Nothing is stopping external people using the API now, except that if they have issues we aren’t prioritising their fixes.
It does come to the crux of the question - do we want to release ‘officially supported’ endpoints in an agile way as we are happy with specific endpoints? Or do we want to an ‘all or nothing’ approach in which we don’t support any endpoints until we have a ‘complete’ set.
This feels more like a communication challenge to me. I’ll add the communication question to the Product dot points.
Definitely! That’s why I wanted to be sure ![]() The “official” and “supported” can be understood very differently. But we are on the same page
The “official” and “supported” can be understood very differently. But we are on the same page ![]()
I’m all in to go there bits by bits, the “big release” makes no sense. But then:
How do we communicate our API releases/roapmap/release plan?
For tax reports do we really need to communicate an API roadmap? To me the easiest here is to say that we have prioritized Tax reports, technically we will start developing our API with that, but as we are really in early stages I wouldn’t commit to anything further at this point. We need to go easy on us. All the questions you have listed will already be a nice challenge, let’s go step by step.
In short I don’t thing a release plan for the API is needed to move forward with Tax reports.
Re
My gut feeling is to start with the use case of Tax reports, and handle s2 on that use case first. Once we have more use cases we can decide how to prioritize them?
We do this in on the OFN product as well (we need a name for this product haha): if the bug is related to a use case that rarely happens or outside of a scope we have identify before it is something that is either an s3 either something that needs inception before anything is done.
I would stick to the same process. I’m not saying it is perfect and we shouldn’t change it, but as a start treating both our products with the same processes sounds the easiest?
As an API is an interface between machine and machine, it is very safe and confortable (because it’s supposed to be idempotent) to put automated testing (way more easier that automatic testing the UI !).
I think we should address this issue about JSON structure before we do anything else, it applies to all existing endpoints and all future endpoints. We’ll be limited in our choices later if we don’t do this early on. It involves some relatively small breaking changes (good ones) and includes some nice cleanup/standardisation in places that are currently messy and non-standarised.
There’s also the switching from AMS to fast_jsonapi issue that has previously been discussed, but I think it might need a spike and some discussion. TLDR; it could give us 20-30x faster performance in JSON serialization (which is insane), but it would also impose a slightly different structure in some of our JSON. It would probably involve some work in adapting the parts of our app that currently consume the API, but it’s not clear how much. This would also introduce breaking changes, and it’s probably a now-or-never choice. We wouldn’t want to do this after the API is more widely used. The eye-watering performance boost is a no-brainer, but I’m not sure if this switch would be feasible at the moment.